前端面试题
纪录自己学习中所遇到的面试题
HTML
对HTML语义化的理解?
语义化就是根据标签的名字就能想到标签的作用或者布局(见名思意),正确的标签做正确的事。
优点:
- 代码结构更加清晰明了,不看 css 代码也能很快了解页面的布局结构
- 对 seo 优化更好,方便爬虫更有效的爬取页面主体信息
- 语义化的标签也更方便读屏软件,让每一部分都有意义
常见的语义化标签:
<header>头部区域</header>
<nav>导航栏</nav>
<article>文章</article>
<main>主体区域</main>
<aside>侧边栏</aside>
<footer>底部</footer>说一下你对盒模型的理解?
盒模型有两种: 标准盒模型和IE盒模型(怪异盒模型)
标准盒模型的 width 和 height 只包括 Content ,box-sizing: content-box
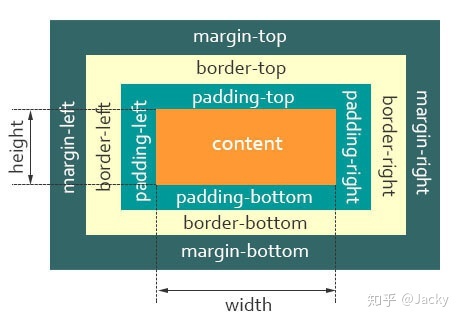
IE 盒模型的 width 和 height 包括 border padding content, box-sizing: border-box
CSS
::before 和 ::after的作用是什么? CSS3中单冒号 :和双冒号 :: 的区别是什么?
单冒号是伪类,表示被选中元素的某一种状态,例如 :hover ,
双冒号是伪元素的标识符,表示被选中元素的某个部分,这个部分看起来像独立的元素,但是这个元素是假元素并不存在,所以叫伪元素。例如::before和 :after
说一说 position 的属性已经分别相对于什么定位?
relative元素的定位永远是相对于元素自身的位置,和其他的元素没关系,也不会影响到其他元素,不脱离文档流fixed元素的定位是相对于 window 窗口边界的,和其他元素没有关系,但是它具有破坏性,会导致其他元素位置的变化,脱离文档流absolute: 它会找到一个离他最近的设置了position: relative/absolute/fixed的元素定位,如果没找到,就以浏览器边界定位,脱离文档流定位。sticky在position:relative与position:fixed定位之间切换。在元素定位表现为跨越特定阈值前为相对定位,之后为固定定位inherit继承父元素的定位值来进行定位
如何居中下面代码中的 .middle 元素? 水平居中? 垂直居中?
.container {
width: 600px;
height: 600px;
padding: 0;
margin: 0;
border: red 1px dashed;
}
<!-- html -->
<div class="container">
<div class="middle"></div>
</div>- 水平居中
/* 给 middle 块级元素设置长宽,并设置 margin */
.middle {
margin: 0 auto;
width: 10px;
height: 10px;
}- 垂直居中
/* 1.使用flex 布局 */
.container {
display: flex;
justify-content: center;
align-items: center;
}
/* 2. 使用grid 布局 */
.container {
display: grid;
justify-content: center;
align-items: center;
}
/* 3. 使用绝对定位 */
.container {
position: relative; // 子绝父相
}
.middle {
position: absolute;
top: 50%; // 移动容器的一半
left: 50%;
translate: -50% -50%; // 补偿的子元素一半
}说一下 BFC ,以及BFC有什么优缺点?
BFC又叫块级格式化上下文,是一种常见的布局手段,主要是为了创建出一个块独立的区域, 不受外部元素的干扰,让其内部元素更好的在这片区域中布局。
应用:
- 阻止
margin覆盖 - 阻止元素被浮动元素覆盖
- 清除内部浮动(父元素高度塌陷问题)
常见的几个触发方式
float不为 noneoverflow不为 visibledisplay为 inline-block ,table-caption 或 table-cellpostion不为 static 或 relative
如何实现一个上中下三行布局,顶部和底部最小高度是100px,中间自适应?
.container {
display: flex,
height: 100%,
flex-direction: column,
}
.top {
min-height: 100px;
}
.middle {
flex-grow: 2;
}
<div id="container">
<div class="top">a</div>
<div class="middle">b</div>
<div class="top">c</div>
</div>实现左右两侧固定宽度,中间不固定三栏布局,有那些方法?
- 使用 flex 实现
外层盒子设置 display: flex ; 左右两个盒子设置 width: 100px, 中间盒子设置 flex: 1
- 使用 grid 布局
外层盒子设置 display: grid, grid-template-columns: 100px 1fr 100px
- 浮动 + calc实现
三个并列的盒子,左侧盒子设置 float: left 中间设置:float: left; width: calc(100% -200px) 右侧盒子设置 float: right
- 浮动 + margin 实现
左侧盒子设置 float: left ,中间盒子设置 margin: 0 100px ,右侧设置: float: right
CSS中选择器的优先级(权重)?
!import > 行内(1000) > id选择器(100) > class选择器(10) > 标签选(1)> 统配选择器(0)
同一个花括号中设置相同的属性,以最后的为准,后面的会覆盖前面的样式,样式冲突的时候就要考虑权重了
代码输出篇
代码执行的结果
var scope = "xiaomai";
function fn() {
console.log(scope);
scope = "xiaomai5";
console.log(scope);
var scope = "xiaomaiketang";
console.log(scope);
}
console.log(scope);
fn();// 执行结果
xiaomai
undefined
xiaomai5
xiaomaiketangsetTimeout 代码执行结果
// 这里如果使用 var 和 let 结果是不一样的
for (var i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, 1000);
}
console.log(i);var的情况
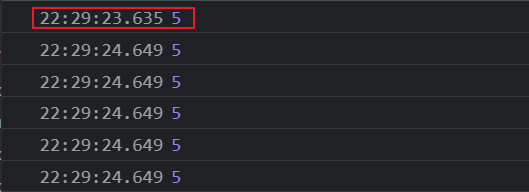
先打印出5 一秒钟之后连续输出5 个 5
let的情况
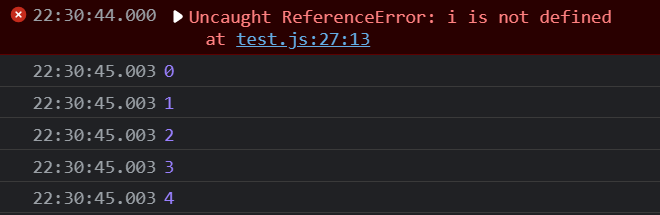
先报错,一秒之后打印出 1,2,3,4
代码执行结果
setTimeout(() => {
console.log("aaa");
}, 0);
new Promise((resolve) => {
console.log("bbb"); // 此处都没有调用 resolve
}).then(() => {
console.log("ccc");
});
console.log("ddd");
// bbb
// ddd
// aaaJavaScript
说一说 const var 和 let 区别,并写出以下代码输出的结果。
| 区别 | var | let | const |
|---|---|---|---|
| 是否存在变量提升 | √ | × | × |
| 块级作用域 | × | √ | √ |
| 是否添加全局属性 | √ | × | × |
| 是否允许重复声明 | √ | × | × |
| 能否修改内存指向 | √ | √ | × |
| 是否存在暂时性死区 | × | √ | √ |
const user = { name: "jack", age: 12 };
user.age++;
user.name = "mike";
// 结果1 : {name: "mike", age: 13}
console.log(user);
user = { name: "jack", age: 12 };
// 结果2 : Uncaught TypeError: Assignment to constant variable.
console.log(user);const 声明的变量不可以被重新赋值
== 和 === 的区别?
== 操作符会对数据做隐式类型装换,再进行值得比较,全等不会做类型转换
基本数据类型和引用数据类型的区别? 堆内存和栈内存?
JavaScript中的数据类型分为两种,基本数据类型和引用数据类型,也可以叫做可变数据类型和不可变数据类型。
基本数据类型主要包括:Number,string, boolean,null,undefined,symbol,bigInt
引用数据类型:Object
区别
- 基本数据类型不可变,引用数据类型数据可变
- 基本数据类型存放在栈内存中,引用数据类型存放在堆内存中
两种内存存储方式区别:
- 栈内存: 一种特殊的线性表,具有后进先出的特性,存放基本类型,数据简单大小确定
- 堆内存: 存放引用数据类型,在栈内存中存一个基本类型值(指针就是这个变量名)保存对象在堆内存中的地址,用于引用这个对象,数据类型复杂大小不固定
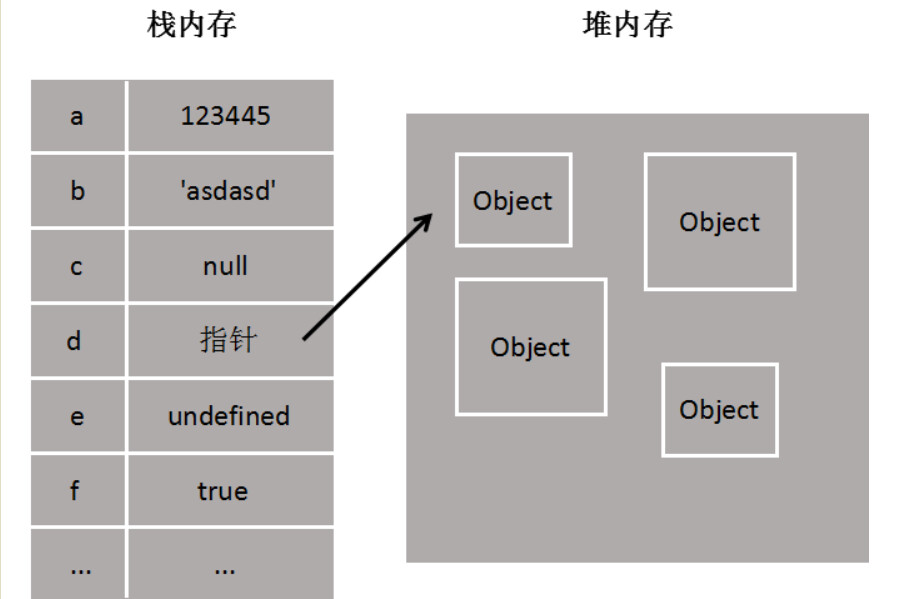
null 和undefined 的区别?
js是弱类型的语言,变量本身是没有类型的,只有变量内存储的数据才有类型,所有未定义,未赋值的变量都是 undefined .简而言之就是 没有值
统计数组元素出现的次数
有一个数组arr,统计出数组中每个元素的出现次数
arr = ['dog','cat','tiger','cat','duck','dog','cat']// 每次遍历item的时候,初始对象中如果没有该元素则添加,元素已存在就对值加一
function count(arr) {
return arr.reduce((acc,item) => {
acc[item] = acc[item] ? acc[item] + 1 : 1;
return acc
} ,{})
}什么是闭包? 闭包的作用是什么?
闭包就是能够读取其他函数内部变量的函数,基本形式就是一个函数内部返回一个函数。
好处:
- 可以读取函数内部的变量
- 将变量始终保持在内存中
- 可以用来封装对象的私有属性和私有方法
function Bird() {
let hatchedEgg = 10;
// 此处为了让 hatchedEgg 不被外部访问到, 使用闭包来保护对象不被外部修改
// 此处的变量和下面的函数都是在同一个上下文中声明的,在js中函数总是可以访问创建同一上下文的变量
this.getHatchedEggCount = function() {
return hatchedEgg;
};
}
let ducky = new Bird();
ducky.getHatchedEggCount();说一说常见数据类型检测的几种方式?
typeof : 用来判断一个变量时否是为原始数据类型,如果是对象或者null,返回 Object
instanceof : 只能判断引用数据类型,判断变量是否时指定对象的实例
constructor : 既可以判断数据类型,也可以用来通过对象实例的 constructor对象来访问它的构造函数
Object.prototype.toString.call(): 通用性最好也最准确的箭头函数和普通函数的区别?
- 箭头函数更加简洁,一般作为回调函数使用
- 箭头函数没有自己的this,它的 this 只是上下文中继承的 this
- 箭头函数没有 arguments,prototype,也不能作为构造函数使用
new 操作符做了些什么?
new 运算符创建一个用户自定义的对象实例。
function Bird() {
this.name = "Albert";
this.color = "blue";
this.numLegs = 2;
}
let blueBird = new Bird();- 创建一个新的空对象,{}
- 设置原型,将构造函数的 prototype属性赋给新对象内部的 [[Prototype]]
- 让函数的 this 指向这个新创建的对象,执行构造函数中的代码(为新对象添加各种属性)
- 判断构造函数是否有返回对象,有则返回该对象,否则返回新创建的对象
说一说 ES6有那些新特性?
- let const
- 模板字符串
- 箭头函数
- set map
- promise
- class
- 解构赋值
- 展开运算符
EventLoop
由于 JavaScript 是单线程的,包含了同步任务和异步任务。同步任务放入 调用栈(主线程) 中执行,异步任务会放到 消息队列中,等待主线程中的任务执行完毕后再取出来执行,而这个时候如果异步任务中任有异步 任务,则会继续放入消息队列中等待
手写源码系列
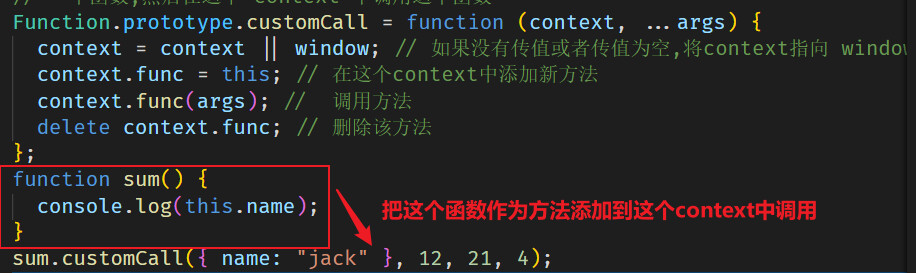
Call
call: 改变当前函数执行时候内部的this,实现过程就相当于在 context 中添加了一个函数,然后在这个 context 中调用这个函数
Function.prototype.customCall = function (context, ...args) {
context = context || window; // 如果没有传值或者传值为空,将context指向 window
context.func = this; // 在这个context中添加新方法,此处的this就是值这个函数
context.func(args); // 调用方法
delete context.func; // 删除该方法
};
apply
作用和call差不多就是第二个参数是数组
Function.prototype.customApply = function (context, arr) {
context = context || window;
arr = arr ? arr : [];
const funcKey = Symbol();
context.funcKey = this;
const result = context.funcKey(arr);
delete context.funcKey;
return result;
};bind
返回一个绑定好this的函数,bind调用的时候可以传参,掉后之后返回的新函数也可以传参,效果一样所以也需要处理
Function.prototype.customBind = function (context, ...args) {
const fn = this; // 接收原函数
args = args ? args : []; // 判断接收的剩余参数存在与否
return function (...newFnArgs) {
return fn.apply(context, [...args, ...newFnArgs]);
};
};Array.forEach
对数组的每一项执行回调函数
Array.prototype.customForEach = function (callback) {
// 此处的this就是这个数组,回调函数中包含三个参数
for (let i = 0; i < this.length; i++) {
callback(this[i], i, this);
}
};Array.map
返回经过处理的数组
Array.prototype.customMap = function (callback) {
let res = [];
for (let i = 0; i < this.length; i++) {
res[i] = callback(this[i], i, this);
}
return res;
};Array.Every
数组每一项都符合处理条件就返回 true,否则返回 false
Array.prototype.customEvery = function (callback) {
for (let i = 0; i < this.length; i++) {
if (!callback(this[i], i, this)) {
return false;
}
}
return true;
};Array.some
数组中只要有一项不返回条件就返回 true ,否则就返回 false
Array.prototype.customSome = function (callback) {
for (let i = 0; i < this.length; i++) {
if (callback(this[i], i, this)) {
return true;
}
}
return false;
};Array.Filter
过滤出处理条件为 true 的数组项目
Array.prototype.customFilter = function (callback) {
let res = [];
for (let i = 0; i < this.length; i++) {
if (callback(this[i], i, this)) {
res.push(this[i]);
}
}
return res;
};Array.reduce
reduce 数组累计结果
Array.prototype.customReduce = function (callback, initVal) {
// 上一次调用的结果,函数第一次调用的时候就是初始值
let preVal = initVal ? initVal : this[0];
for (let i = 0; i < this.length; i++) {
preVal = callback(preVal, this[i], i, this);
}
return preVal;
};new 操作符
function customNew(constructor, ...args) {
// 1. 定义一个空对象
const obj = {};
// 2. 此方法设置一个指定对象的原型,即内部[[Prototype]]属性到另一个对象
Object.setPrototypeOf(obj, constructor.prototype);
// 3. this指向空对象,并执行构造函数
const result = constructor.apply(obj, args);
// 4. 判断构造函数有无返回值,这个值是否为对象
return result instanceof Object ? result : obj;
}deepClone深拷贝
- 浅拷贝: 就是将一个对象的内存地址直接复制给另一个对象
- 深拷贝: 先创建一个对象,内存中创建一个新地址,然后把被复制的对象的所有可枚举的属性方法一一复制过来。
js中的数据分为引用数据类型和基本数据类型,基本数据类型的拷贝复制是直接创建新的副本和原本数据不相关,引用数据类型直接拷贝的话仅仅是拷贝了其指针
-
手写:覆盖了基本数据类型,数组和简单对象,正则表达式,日期类型,Map,Set
处理循环引用
这里用到了
weakMap,特点是只接受 对象作为 key 存储键值对。当需要拷贝当前对象时,先去存储 Cache 中寻找,有的话直接返回
function deepClone(source) {
// 如果源数据是 null 或者 基本数据类型直接返回
if (source === null || typeof source !== "object") return source;
// 处理正则表达式
if (source instanceof RegExp) return new RegExp(source);
// 处理 Date 类型
if (source instanceof Date) return new Date(source);
/*
利用函数本身也是对象的特点,存放缓存解决针对引用数据类型中循环引用的问题,
设置一个缓存,如果拷贝过这个对象了直接返回,没有的话继续执行下面的代码
*/
let cache = null;
if (!deepClone.cache) {
deepClone.cache = new WeakMap();
}
cache = deepClone.cache;
if (cache.has(source)) {
return cache.get(source);
}
// 处理 Map 类型
if (source instanceof Map) {
const map = new Map();
cache.set(source, map);
source.forEach((val) => {
map.set(deepClone(val));
});
return map;
}
// 处理 Set 类型
if (source instanceof Set) {
const set = new Set();
cache.set(source, set);
source.forEach((val) => {
set.add(deepClone(val));
});
return set;
}
// 处理其他引用类型的数据,例如:对象或者数组
const temp = new source.constructor();
cache.set(source, temp);
for (let [key, val] of Object.entries(source)) {
temp[key] = deepClone(val);
}
return temp;
}JSON.parse(JSON.stringify(obj));,有弊端:会忽略 undefined, symbol,和函数,还不能解决循环引用的问题- 浏览器中实现了
StructuredClone(),比较新的方法兼容性差 - 使用
lodash或者Ramda库来实现
debounce防抖函数
防抖或者节流都是为了限制函数的执行次数,避免短时间内进行大量的重复执行。
通过setTimeout 的方式,在一定时间的间隔内,将多次触发只执行一次触发
要点
- 每次调用取消抖动函数之前先清除上次的挂起的超时定时器,然后再创建新的 bounce 函数
- 使用 apply 将 this 提供给调用的函数
- 使用默认参数,将延迟值设为 0
const debounce = function(fn,ms=0) {
let timer;
return function(...args) {
clearTimeout(timer)
setTimeout(() => fn.apply(this,args),ms)
}
}throttle节流函数
一个时间段内,只触发一次
- 版本一,定时器,定时一定时间周期之内,如果这个定时器还存在就返回操作,定时器清空后重新计时
function throttle(fn, delay = 1000) {
let timer;
return function (...args) {
if (timer) {
return;
}
timer = setTimeout(() => {
fn.apply(this, args);
timer = null;
}, delay);
};
}- 版本二,时间戳,如果现在的时间与之前的时间间隔大于延迟,才能执行函数并更新上一次的延迟时间
function throttle(fn, delay = 1000) {
let pre = 0
return function(...args) {
let now = new Date()
if(now - pre > delay) {
fn.apply(this,args)
pre = now
}
}
}手写 Promise.all
// 手写 promise.all 方法
function PromiseAll(arr) {
// 1. 首先这个函数需要返回一个 promise
return new Promise((resolve, reject) => {
// 判断入参是否为数组
if (!Array.isArray(arr)) {
return reject(new Error("传入的参数必须为数组"));
}
const res = [];
// 2. 累计有没有 resolve 掉所有的 promise
let counter = 0;
arr.forEach((val, idx, arr) => {
Promise.resolve(val)
.then((result) => {
counter++;
res[idx] = result;
if (counter === arr.length) {
// 3. 全部都resolve 掉后, resolve出所有结果
resolve(res);
}
})
.catch((err) => reject(err)); // 处理错误结果
});
});
}数组扁平化
// 1. 方法一,如果数组中全是数字的话要转成数字
function flatten(arr) {
return `${arr}`.split(",").map((i) => +i);
}
// 2. 方法二, 递归
function flatten(arr) {
let res = [];
for (let item of arr) {
if (Array.isArray(item)) {
res.push(...flatten(item));
} else {
res.push(item);
}
}
return res;
}
// 3. ES6实现
function flatten(arr) {
debugger;
while (arr.some((i) => Array.isArray(i))) {
arr = [].concat(...arr);
}
return arr;
}数组去重
// 方法一 声明新数组,forEach遍历数组,判断目标数组中是否有原数item,如果没有则添加
function fn(arr) {
let res = [];
arr.forEach((item) => {
if (!res.includes(item)) {
res.push(item);
}
});
return res;
}
// 方法二 新建Set集合(集合中的值只能出现一次),对集合进行展开
function fn(arr) {
return [...new Set(arr)];
}
// 方法三 使用filter过滤
function fn(arr) {
return arr.filter((item, index) => {
return arr.indexOf(item) === index;
});
}
// 方法四 使用reduce, 第二个参数为空数组,每次遍历迭代时,判断空数组中是否有item,
// 如果有的话直接返回累加器,没有的话返回新数组
function fn(arr) {
return arr.reduce((pre, item) => {
return pre.includes(item) ? pre : [...pre, item];
}, []);
}数据类型判断实现
typeof 可以正确判断: undefined 、Boolean、Number、String、Symbol、Function等类型的数据
但是其他的数据都会认为是 object,比如:Null ,Date等,所以原生的typeof函数判断数据类型并不准确
function typeOf(obj) {
return Object.prototype.toString.call(obj).slice(8,-1).toLowerCase()
}浏览器
请描述下 cookie, session 和 localStorage 的区别?
- 生命周期
cookie: 可以设置失效时间,expires或者 max-age 不设置的话页面关闭就失效localStorage: 除非手动删除,否则永久保存sessionStorage: 仅在当前网页会话下有效,关闭页面或者浏览器后就会被清除
- 存放数据大小
cookie: 94年就被发明出来的,由于网络带宽小所以只有4kB左右的大小localStorage和SessionStorage: 可以保存5MB大小的信息
- http请求
cookie: 每次都会携带在 http 头部中,如果 cookie 保存过多的数据会带来性能问题localStorage和sessionStorage: 仅在浏览器中保存,不参与和服务端的通信
浏览器路由的 Hash 和 history 有什么区别?
- hash 模式
hash路由通过监听 location 对象的 hash 值发生改变得时候会触发 onhashchange 事件。
特点:
- 哈希路由变化会触发网页跳转,即浏览器得前进和后退。
- 兼容性比较好
- 不太美观,地址栏中会有 # 号。
- history模式
history 是h5 新提供的特性,可以做到无刷新得更新浏览器地址而不需要重新发起请求。主要用到了 history 对象的 pushState 方法
特点
- 使用简单,比较美观
- api 较的缘故,低版本浏览器会不兼容
- 前端的 URL 必须想发送请求的后端 URL 保持一致,需要后端配合不然会产生404 错误
history路由模式的问题:
该模式不怕地址前进和后退,就怕刷新,如果打开一个页面的二级页面刷新页面会产生 404 错误。因为此时刷新页面是实实在在的请求服务,我要得到这个页面。而这个页面在服务那边是不存在的 而hash模式就不会有这个问题,因为此时前端路由修改的是 # 中的信息,浏览器在请求服务器的时候 是不包含这部分的,所有不会有找不到文件的情况.
解决方法,在 nginx 中进行配置
location / {
try_files $uri $uri/ /index.html;
}浏览器跨域解决方案
jsonp(利用script标签,前端需要定义一个回调函数接受数据,兼容性好,但是只能发送 get请求)CORS(需要服务器端支持)- 使用
websocket - 使用
Nginx进行反向代理
浏览器缓存策略
cookie: 有过期时间,长度限制在 4kb左右,每次都会携带在请求头重,不推荐使用SessionStorage无过期时间,容量大,但是窗口一旦关闭就会自动删除localStorage无过期时间,容量大概5M左右indexedDB存储更大量的结构化数据,浏览器本身不受限制其容量
http网络
说一下常见的 http 状态码?
1xx: 表示消息已经接收,继续处理 -->
101 Switching Protocols: 切换协议
2xx:成功,表示请求已经被成功接收处理
200 ok,客户端请求成功
204 No Content : 无内容,服务器成功处理,但未返回内容
206 Partial Content: 客户端进行了范围请求,服务端成功执行了范围响应
3xx 重定向,表示浏览器需要执行某些特殊的处理来正确的处理请求
301:Moved Permanently: 永久重定向,表示请求的资源已被永久的移动到新的 url 地址中,返回的信息中包含新的 url 地址,浏览器自动定向到这个新地址,以后每次请求都使用这个新地址
302: Found: 临时重定向,表示请求的资源临时搬到了其他位置
4xx 客户端错误
400 :Bad Request: 客户端的请求有语法错误,服务器无法理解
401: Unauthorized: 请求未经授权,用户未没有进行身份验证
403: Forbidden: 服务端理解了请求,但是拒绝服务
404: Not Found 请求的资源不存在
405: Method Not Allowed: 请求的方法不支持
5xx 服务端错误
500: Internal Server Error: 服务器内部错误,无法完成请求
502: Bad Gateway: 网关错误
HTTP 1.x/2.x/3.0的区别?
http1.x
- 通过
keep-alive来保持长久连接,即Tcp连接在发出请求后不会立刻关闭,可以被多个请求复用 队头阻塞问题限制并发性能(通过减少请求或域名切片来优化)- 由于无状态,一个页面的加载中多次请求中需要发送多次重复的
cookie来维持会话,导致请求体积增大应用性能
http2
- 通过二进制(帧)来传输数据(哈夫曼编码)
- 使用
hpack压缩格式,压缩请求和响应标头元数据 - 使用报头压缩,降低开销
- 服务端可以主动推送静态资源给客户端
http3
- 基于
udp实现,速度更快
强缓存和弱缓存?
React
什么是虚拟dom?
虚拟 dom 是将真实的 dom 元素抽象保存在内存中,更加轻量和实际 dom 保持同步。
虚拟dom的优点?
- 真实
dom太重了,频繁操作dom元素性能和效率会很低。使用虚拟dom可以提高浏览器的性能。 - 操作虚拟
dom并不是都是提高性能的,简单的项目中创建虚拟dom反而不如直接操作 - 虚拟
dom也可以实现跨平台的渲染,小程序,服务器都可以使用
声明组件的方式,有什么不同和优缺点?
类组件和函数式组件
-
函数式组件和类组件,都必须是纯函数,不能修改他们自己的props,
-
类组件有自己的 state 和 生命周期函数,而函数式组件没有
-
类组件由于使用的时候需要实例化,所以性能相比于函数式组件会差点
什么是高阶组件?
高阶组件(hoc) 并不是 react 提供的一项 api,而是一种设计模式将不同子组件组合返回一个新组件的函数。 他不会修改或者复制输入组件中的任何行为。
什么是受控组件和非受控组件?
受控组件的 value 属性是和 react 中的 state 状态进行绑定的,组件内部通过传递onChange 事件来处理值的变化。
非受控组件更像是传统的 html 表单元素, 数据存储在 DOM 中,用户提交表单时候,随着表单一起发送出去。
尽可能使用受控组件,将状态由 react 来接管。
为什么不能直接更新 state 呢?
直接更新 state 不会渲染组件,需要使用 setState() 方法来更新,通过这个方法来调度 state 对象的更新,当 state 改变时候, 组件通过重新渲染来响应。
setState 是同步还是异步?
React性能优化?
React 中组件和组件之间有那些通信方式?
- 父组件给子组件通过 props 来传递信息,子组件通过事件向父组件传递信息
- 使用内部的两个 hooks, useContext, useReducer
- 使用状态管理库,比如 redux,hox,mobx 来实现跨组件之间进行通信
React组件map中的key 的作用是什么?
- key 可以帮助 react 识别那些元素发生了改变,比如元素被添加或者删除。有利于提高程序运行和渲染效率
- react 的虚拟dom通过使用diff算法对比更改前后发生的最小差异,然后再对真实dom进行修改,使用key 主要是为了标记前后两次渲染中元素的对应关系,放置不必要的更新操作。
- key 的取值需要在兄弟元素中保持唯,所以不能使用数组的index来替代,如果数组插入数据或者重新排序后,原先的 index 就不能对应到原来的值,这个key 就是失去了意义
redux 的工作流程?
核心概念
store: 保存数据的地方,可以看成一个容器,整个应用只能有一个storestate:store对象包含所有数据,如果想得到某个时间点的数据,就要对store生成快照,这种时间点的数据集合就叫做stateAction:state的变化,会导致view的变化,但是用户接触不到state,只能接触到view,Reducer将state和action作为参数返回新的statedispatch: 是view发出action的唯一方法
- 用户,操作界面视图层发出
Action,发出方式用到了dispatch方法 store自动调用reducer,并且传入两个参数,当前的state和收到的action,Reducer会返回新的statestate一旦有变化,store就会调用监听函数,用来更新view
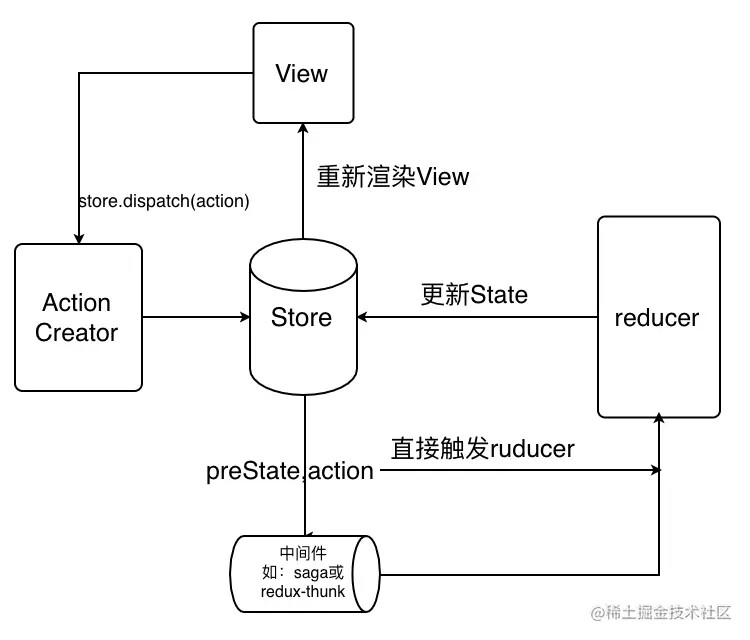
其他
从键盘输入 URL 开始到浏览器页面加载完成的过程中都发生了什么事情?
- DNS解析: 将输入的域名解析成主机对应的 ip 地址
- TCP 连接: TCP 三次握手
- 发送 HTTP 请求
- 服务器处理请求返回 HTTP 报文
- 浏览器解析请求的数据并加载 dom 树渲染页面
- 断开连接: TCP 四次挥手
项目性能优化有那些方式?
webpack 相关
Loader 和 Plugin 的区别?
Loader(加载器),webpack 中将一切文件都视为模块,未经配置的webpack只能解析js文件,如果想要打包其他文件的话,就需要使用到loader,其最大的作用就是让webpack拥有加载和解析非js文件的能力。Plugin(插件) : plugin可以扩展 webpack 的功能,让 webpack 有更多的灵活性,webpack 在运行的生命周期中会广播出许多事件,plugin可以监听这些事件,在合适的时机,通过 webpack 提供的 api 改变输出结果。
有那些 webpakck 优化前端性能的方案?
HR面试相关
做个简单的自我介绍
- 自己的情况,技术栈和自己的项目
为什么要干前端?
平时是怎么学习前端的?
你觉得你的优势和不足是什么?
优势
- 对于感兴趣的技术学习的动力非常强,愿意和周围的朋友分享
- 关心最新的行业动态,时刻保持好奇心
不足
不感兴趣的内容学习不下去,比如数据库
你还有什么想问我的?
- 公司的产品主要技术栈,开发流程是怎样的
- 前后端的配比情况
- 如果我入职了,具体的开发职责
- 福利待遇,加班调休
对未来的职业规划?
- 继续打牢前端最基础的三大件
- 短期任务学好
ts,长期任务学习node相关 - 提高自己的表达能力和沟通能力
回答面试题的方法
- 讲:讲概念,一句话解释技术本质
- 说: 说用途,简短说明技术用途
- 理: 理思路,概要说明核心技术思路
- 列: 优缺点,独特优势和个别缺点
面试官打招呼
首先,第一点,总结提炼自己的定位、方向、优势、业绩、态度。尽可能用数字高度话概括自己的工作内容、工作业绩。
比如:
211本科人力资源管理专业毕业;
有3年房地产行业人力资源全盘工作经验,招过184人,组织过35场活动和培训,输出过4个培训课件等等;
希望能够在房地产行业人力资源领域深耕发展,公司所需经验,我都具备,有能力能够胜任。
第二点,能分点就分点,能分行就分行,造成视觉美观,便于快速阅读,抓住重点。
第三点,字数一定要适量!不要太多,也不要太少。我相信hr没时间去看一篇小作文,咱们也没必要写的这么具体。具体的东西留给hr面试的时候像你提问和自己的进一步展示。大概在50-100字之间比较合适。
第四点,客套话要到位,开头一定要缓场,一定要先问候hr,介绍自己,再复制自己的介绍。结尾也要固定写上期待语。比如感谢您百忙抽空查看我的简历,十分期待贵司的回复。
另外,大家一定要记住,开篇一定不要全部都只写您好。你能看到这公司的招聘负责人是谁吧,上面都有写xx经理,xx负责人xx总监,稍微用点心,在前面加上,王经理您好,balabala...
所以完整的回复语就是:
王经理,您好,我是xx。
.....
感谢您百忙抽空查看我的简历,十分期待贵司的回复!
我相信每个hr都会认为你是用心看过招聘信息才投递的,不是海投的,也不是系统推荐的。
第五点,一定要记得,打完招呼语,如果面试官回复了,就主动发份简历过去。
第六点,如果你有多个岗位应聘方向,那侧重点一定是不一样的,还要定制化不同的简历、不同的总结。
第七点,和大家再次强调下,第一印象真的很重要,哪怕目前的岗位不够适合你,但是如果hr对你印象不错,说不定会直接把你推荐给其他公司,同行hr的圈子,或者放到自己的人才库中。
第八点,这段招呼语也可以放在简历中的自我评价环节,这两部分,本质上是一样的目的哟!就是为了让面试官通过你的自我认知快速了解你的经验水准、能力水平。